Storm 初探
打算把自己学习实时计算的相关东西写出来,形成一个从零开始学实时计算的系列,由于我也是刚开始接触,系列文中的描述或概念有不当的地方,还请不吝指教。在此谢过。
Storm 是一个分布式实时计算框架,由 Twitter 开放并开源。用来处理无边界的流数据,进行实时处理。与 Hadoop 做批处理相对应。因为底层使用 Thrift 来定义和提交 Topology(Storm 中的一种结构),Storm 可以使用任何语言来进行编程。可以用来做实时计算,在线机器学习等等一系列事情。每秒可以每个节点可以处理百万级别的 Tuple(Storm 中的一种结构)。伸缩性好,容错好,并且保证所有数据都会被处理。
首先介绍 Storm 中几个结构的定义,分别是 Tuples, Stream, Spout, Bolt, Topology, Task.
- 其中 Tuple 是最基本的结构,是传输数据过程中的最小单元,可以当作为一个包装好的结构体
- Stream: 是无边界的 Tuple 组成的数据流,可以理解为 Tuple 的流动
- Spout: 是程序的数据来源,由用户指定,指定之后,所有的数据都从 spout 发出
- Bolt: 数据中转和处理的节点,负责经过数据的中转以及处理
- Topology: 是包括 spout,stream,bolt 的一个完整流程,表示数据从开始到结束的整个过程,每一个 Topology 定义了数据的来源,中间需要怎么转换,以及最后输出到哪
- Task: Spout 或者 Bolt 中实际处理数据的单元,每一个 Spout 或 Bolt 可以包含多个 Task
下面的图形象的表示了大部分结构,其中水龙头表示 Spout,写有 Tuple 字样的表示 Tuple,闪电状的结构是 Bolt,多个 Tuple 形成了 Stream,整张图可以看作是一个 Topology。这里没有细分出 Task 结构。
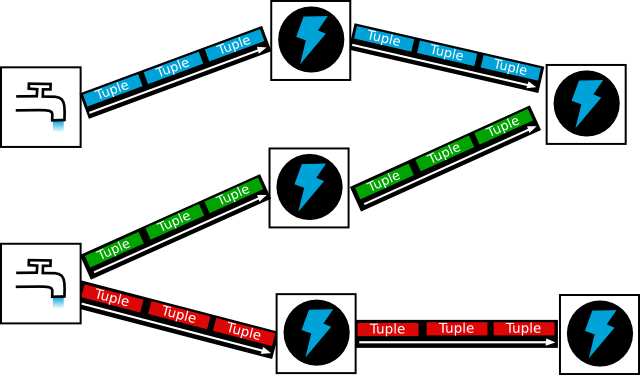](http://storm.apache.org/images/topology.png)
由于 Storm 是分布式的实时处理框架,所有需要一个分配任务的节点,在 Storm 中,这个任务由 Nimbus 担任,所有的 Topology 都是提交 Nimbus 中,由 Nimbus 进行任务分配,Nimbus 会在所有的 Supervisor 中查找最合适的(最空闲),然后把任务分发给它,但是 Nimbus 和 Supervisor 不是直接通信,而是由 Zookeeper 进行中间传话(Supervisor 可以理解为实际的机器,然后 Bolt 会在每一个 Supervisor 上跑,每一个 Supervisor 上有多个 Bolt存在),为什么不让 Nimbus 和 Supervisor 直接通信呢,因为这样可以减少 Nimbus 的负担,Nimbus 只需要把任务分配写到 Zookeeper 就行了,然后 Supervisor 去 Zookeeper 读,每一个 Supervisor 的状态(空闲等情况)也会写到 Zookeeper 上,由 Nimbus 去读。如果是直接通信的话,那么需要 Nimbus 和 Supervisor 同时有空才可以,这样是不太现实的。(比如 A 需要把黄金交给 B,只能直接给的话,必须 A 和 B 同时有空才行,但是总共由四种情况存在:1. A 有空,B 没空;2 A 有空,B有空;3 A没空,B没空;4A没空,B有空。那么只有情况2才可以进行交易,就可能导致 A 一直跑过去找 B,或者B 一直去找 A 的情况,会大大浪费时间)
由于每个 Bolt 有多个 Task 存在,那么对于 Tuple 传给哪一个对应的 Task 处理,就需要进行控制了,这里就有 Grouping 的概念了,Grouping 表示在 Topology 中从上一个节点(Spout/Bolt)到下一个节点(Bolt)时怎么进行 Tuple 的传输(传给哪个 Task)Storm 中包含了 7 中 Grouping 的方式{Shuffle grouping;Fields grouping;Partial Key grouping;All grouping;Global grouping;None grouping;Direct grouping}(对于 Fields 方式,只需要相同字段的分到一组就行了,并不需要不同字段的分到不同组)
基本概念差不多就这些了,我也是刚开始接触,本文内容结合下面几个链接以及自己理解进行书写,如果有错误的地方,还请不吝指教。
References:
1. Apache Storm:http://storm.apache.org/
2. Storm Concepts:https://storm.apache.org/documentation/Concepts.html

