本文作为一个问题追查过程的复盘记录,主要希望找出自己在解决问题中可以优化改进的地方。以后遇到问题,能够快速的进行定位,解决。
Read More实时计算
2017-06-03
2017-01-15
2016-12-16
现象
Spark Streaming 处理数据过程中遇到 Ran out of messages before reaching ending offset 异常,导致程序一直 hang 住(因为我们希望接上次消费从而不丢失数据)
2016-07-15
上一篇文章中,我们讲了如何在将 offset 保存在 zk 中,以及进行重用,但是程序中有个小问题“如果程序停了很长很长一段后再启动,zk 中保存的 offset 已经过期了,那会怎样呢?”本文将解决这个问题
如果 kafka 上的 offset 已经过期,那么就会报 OffsetOutOfRange 的异常,因为之前保存在 zk 的 offset 已经 topic 中找不到了。所以我们需要在 从 zk 找到 offset 的这种情况下增加一个判断条件,如果 zk 中保存的 offset 小于当前 kafka topic 中最小的 offset,则设置为 kafka topic 中最小的 offset。假设我们上次保存在 zk 中的 offset 值为 123(某一个 partition),然后程序停了一周,现在 kafka topic 的最小 offset 变成了 200,那么用前文的代码,就会得到 OffsetOutOfRange 的异常,因为 123 对应的数据已经找不到了。下面我们给出,如何获取
|
|
但是上面的代码有一定的问题,因为我们从 kafka 上获取 offset 的时候,需要寻找对应的 leader,从 leader 来获取 offset,而不是 broker,不然可能得到的 curOffsets 会是空的(表示获取不到)。下面的代码就是获取不同 partition 的 leader 相关代码
|
|
上面的代码能够得到所有 partition 的 leader 地址,然后将 leader 地址替换掉上面第一份代码中的 broker_list 即可。
到此,在 spark streaming 中将 kafka 的 offset 保存到 zk,并重用的大部分情况都覆盖到了
2016-07-14
在 Spark Streaming 中消费 Kafka 数据的时候,有两种方式分别是 1)基于 Receiver-based 的 createStream 方法和 2)Direct Approach (No Receivers) 方式的 createDirectStream 方法,详细的可以参考 Spark Streaming + Kafka Integration Guide,但是第二种使用方式中 kafka 的 offset 是保存在 checkpoint 中的,如果程序重启的话,会丢失一部分数据,可以参考 Spark Kafka - Achieving zero data-loss。
本文主要讲在使用第二种消费方式(Direct Approach)的情况下,如何将 kafka 中的 offset 保存到 zookeeper 中,以及如何从 zookeeper 中读取已存在的 offset。
大致思想就是,在初始化 kafka stream 的时候,查看 zookeeper 中是否保存有 offset,有就从该 offset 进行读取,没有就从最新/旧进行读取。在消费 kafka 数据的同时,将每个 partition 的 offset 保存到 zookeeper 中进行备份,具体实现参考下面代码
|
|
使用上面的代码,我们可以做到 Spark Streaming 程序从 Kafka 中读取数据是不丢失
欢迎阅读第二篇文章,解决 offset out of range 的问题
2015-07-17
打算把自己学习实时计算的相关东西写出来,形成一个从零开始学实时计算的系列,由于我也是刚开始接触,系列文中的描述或概念有不当的地方,还请不吝指教。在此谢过。
本文对 storm 的几种分组方式进行测试,加深对每一种分组方式的理解。首先,storm 包含下面七种分组方式:
- Shuffle grouping: Tuples are randomly distributed across the bolt’s tasks in a way such that each bolt is guaranteed to get an equal number of tuples.
- Fields grouping: The stream is partitioned by the fields specified in the grouping. For example, if the stream is grouped by the “user-id” field, tuples with the same “user-id” will always go to the same task, but tuples with different “user-id”‘s may go to different tasks.
- Partial Key grouping: The stream is partitioned by the fields specified in the grouping, like the Fields grouping, but are load balanced between two downstream bolts, which provides better utilization of resources when the incoming data is skewed. This paper provides a good explanation of how it works and the advantages it provides.
- All grouping: The stream is replicated across all the bolt’s tasks. Use this grouping with care.
- Global grouping: The entire stream goes to a single one of the bolt’s tasks. Specifically, it goes to the task with the lowest id.
- None grouping: This grouping specifies that you don’t care how the stream is grouped. Currently, none groupings are equivalent to shuffle groupings. Eventually though, Storm will push down bolts with none groupings to execute in the same thread as the bolt or spout they subscribe from (when possible).
- Direct grouping: This is a special kind of grouping. A stream grouped this way means that the producer of the tuple decides which task of the consumer will receive this tuple. Direct groupings can only be declared on streams that have been declared as direct streams. Tuples emitted to a direct stream must be emitted using one of the emitDirect methods. A bolt can get the task ids of its consumers by either using the providedTopologyContext or by keeping track of the output of the
emitmethod in OutputCollector (which returns the task ids that the tuple was sent to).
由于测试环境种没有 Partial Key grouping 方式,Direct grouping 方式使用不同的消息发送方式。这里只对其他五种方式进行了测试。
测试环境为:
- Spout 一个,循环发送一百个单词,配置了一个线程
Bolt 一个,统计单词数目,配置了两个线程
测试结果为(下面出现的阿拉伯数字为单词重复的次数):Shuffle 从第一百零八个统计数据出现 2,后面还会穿插出现 1
- Field 从第一百零一个统计数据出现 2,出现方式为一百个个1,然后一百个个 2,然后一百个3….
- Global 从第一百零一个统计数据出现2,出现方式与 Field grouping 方式一样
- All 从第二百零一个统计数据出现2,然后是两百个2,接着是两百个3….
- None 从第一百个统计数据出现 2,后面会穿插着出现 1,次数随机出现,与 Shuffle grouping 方式一样
其中 Shuffle 和 None 都是随机模式,会随机的发送给下一个 Bolt 的任何一个 task。Field 方式会把相同字段的分到同一个 task 上(不同字段的也可以在相同 task 上),Global 方式效果和 Field 一样,根据官方文档,每次都发送给 id 小的 task,All 会发送给 Bolt 上的所有 task(所有上述例子的循环长度为二百),这种方式会浪费比较多的资源。
另外根据文档说明,Partial Key grouping 是在 Field 的基础上进行了压力均衡;Direct 方式需要使用 emitDirect 发送数据。
2015-07-16
打算把自己学习实时计算的相关东西写出来,形成一个从零开始学实时计算的系列,由于我也是刚开始接触,系列文中的描述或概念有不当的地方,还请不吝指教。在此谢过。
Storm 是一个分布式实时计算框架,由 Twitter 开放并开源。用来处理无边界的流数据,进行实时处理。与 Hadoop 做批处理相对应。因为底层使用 Thrift 来定义和提交 Topology(Storm 中的一种结构),Storm 可以使用任何语言来进行编程。可以用来做实时计算,在线机器学习等等一系列事情。每秒可以每个节点可以处理百万级别的 Tuple(Storm 中的一种结构)。伸缩性好,容错好,并且保证所有数据都会被处理。
首先介绍 Storm 中几个结构的定义,分别是 Tuples, Stream, Spout, Bolt, Topology, Task.
- 其中 Tuple 是最基本的结构,是传输数据过程中的最小单元,可以当作为一个包装好的结构体
- Stream: 是无边界的 Tuple 组成的数据流,可以理解为 Tuple 的流动
- Spout: 是程序的数据来源,由用户指定,指定之后,所有的数据都从 spout 发出
- Bolt: 数据中转和处理的节点,负责经过数据的中转以及处理
- Topology: 是包括 spout,stream,bolt 的一个完整流程,表示数据从开始到结束的整个过程,每一个 Topology 定义了数据的来源,中间需要怎么转换,以及最后输出到哪
- Task: Spout 或者 Bolt 中实际处理数据的单元,每一个 Spout 或 Bolt 可以包含多个 Task
下面的图形象的表示了大部分结构,其中水龙头表示 Spout,写有 Tuple 字样的表示 Tuple,闪电状的结构是 Bolt,多个 Tuple 形成了 Stream,整张图可以看作是一个 Topology。这里没有细分出 Task 结构。
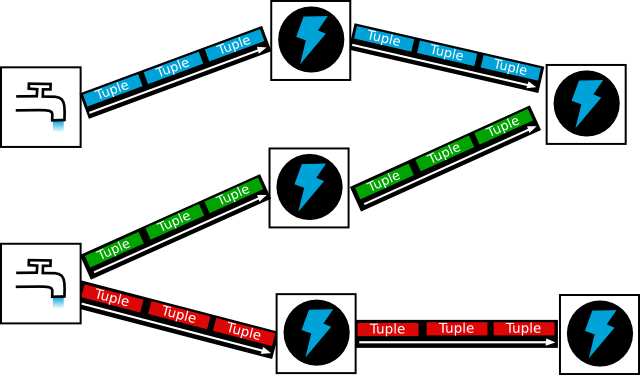](http://storm.apache.org/images/topology.png)
由于 Storm 是分布式的实时处理框架,所有需要一个分配任务的节点,在 Storm 中,这个任务由 Nimbus 担任,所有的 Topology 都是提交 Nimbus 中,由 Nimbus 进行任务分配,Nimbus 会在所有的 Supervisor 中查找最合适的(最空闲),然后把任务分发给它,但是 Nimbus 和 Supervisor 不是直接通信,而是由 Zookeeper 进行中间传话(Supervisor 可以理解为实际的机器,然后 Bolt 会在每一个 Supervisor 上跑,每一个 Supervisor 上有多个 Bolt存在),为什么不让 Nimbus 和 Supervisor 直接通信呢,因为这样可以减少 Nimbus 的负担,Nimbus 只需要把任务分配写到 Zookeeper 就行了,然后 Supervisor 去 Zookeeper 读,每一个 Supervisor 的状态(空闲等情况)也会写到 Zookeeper 上,由 Nimbus 去读。如果是直接通信的话,那么需要 Nimbus 和 Supervisor 同时有空才可以,这样是不太现实的。(比如 A 需要把黄金交给 B,只能直接给的话,必须 A 和 B 同时有空才行,但是总共由四种情况存在:1. A 有空,B 没空;2 A 有空,B有空;3 A没空,B没空;4A没空,B有空。那么只有情况2才可以进行交易,就可能导致 A 一直跑过去找 B,或者B 一直去找 A 的情况,会大大浪费时间)
由于每个 Bolt 有多个 Task 存在,那么对于 Tuple 传给哪一个对应的 Task 处理,就需要进行控制了,这里就有 Grouping 的概念了,Grouping 表示在 Topology 中从上一个节点(Spout/Bolt)到下一个节点(Bolt)时怎么进行 Tuple 的传输(传给哪个 Task)Storm 中包含了 7 中 Grouping 的方式{Shuffle grouping;Fields grouping;Partial Key grouping;All grouping;Global grouping;None grouping;Direct grouping}(对于 Fields 方式,只需要相同字段的分到一组就行了,并不需要不同字段的分到不同组)
基本概念差不多就这些了,我也是刚开始接触,本文内容结合下面几个链接以及自己理解进行书写,如果有错误的地方,还请不吝指教。
References:
1. Apache Storm:http://storm.apache.org/
2. Storm Concepts:https://storm.apache.org/documentation/Concepts.html